
Amazon Review Sentiment Analysis
Github Link: https://github.com/Nsilswal/Amazon-Sentiment-Analysis
Overview
The goal of this project was to utilize sentiment analysis to generate meaning and drive business value through Natural Language Processing on Amazon Reviews. This kind of analysis would be beneficial to a seller on Amazon by enabling them to quickly parse and understand negative reviews to improve the product / experience for the user.

Using sentiment analysis through machine learning could be beneficial to a user in a number of ways. For example, it could help them quickly identify and address negative feedback about their product, making it easier to improve the overall user experience. Additionally, it could provide insights into how users are interacting with the product, which could inform future development and updates.
Data Cleaning
- To reduce the space of vectors our models would be required to work with, we performed several steps to clean the data
- Frequently appearing contractions were mapped to a standard format
- All words were converted to lower case and stripped of special characters, numbers, and punctuations
- Elongated words were reduced to basic versions
- Stop words were removed (with, the, then)
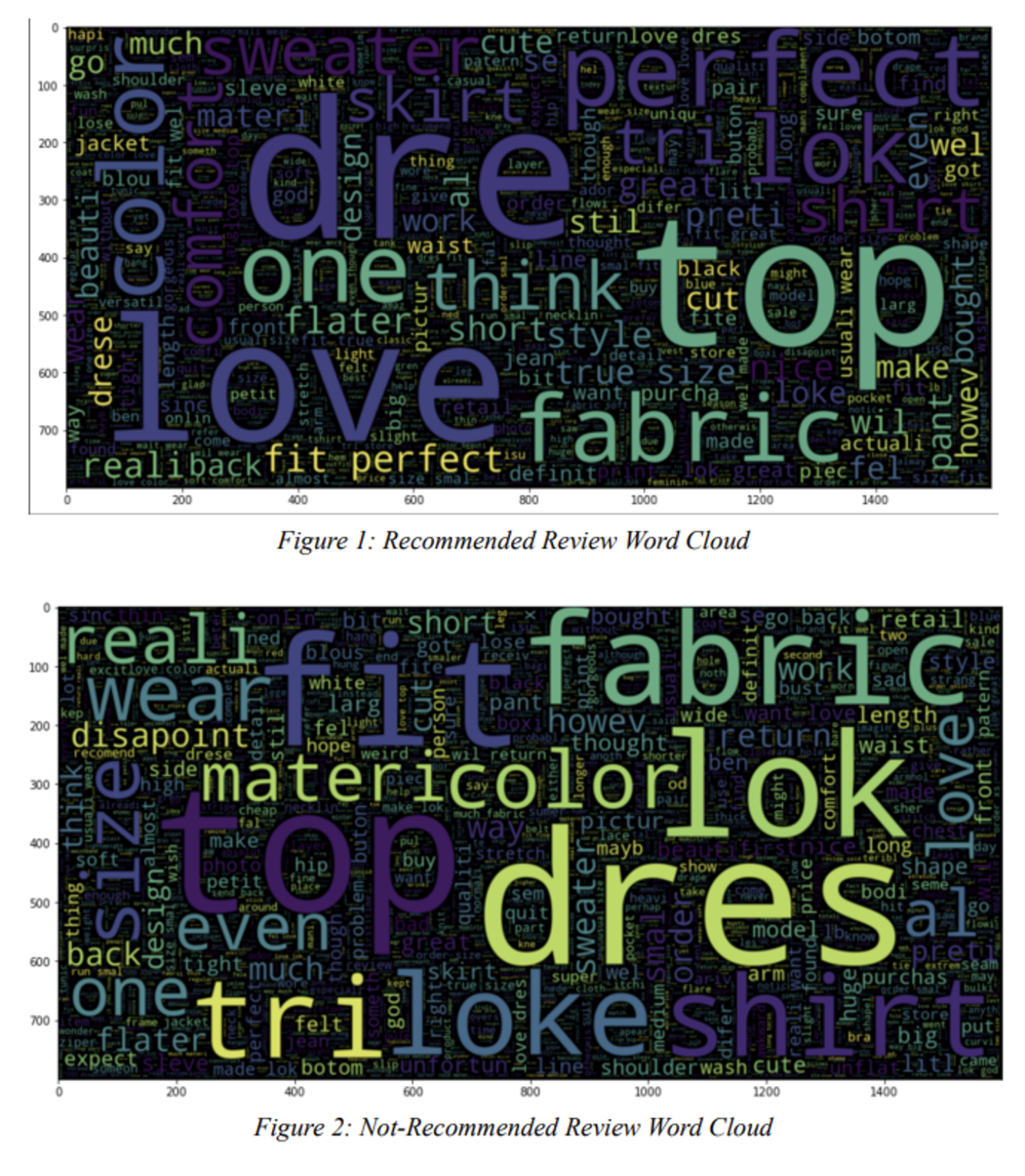
To gain a grasp of what our model should be extracting from the data we generated word clouds to represent words utilized in recommended reviews and not-recommended reviews
Encodings & Tokenization
To begin training the discriminative models on real data, we first had to tokenize our data. Our end goal here is to split up the sentences into their individual words. To begin we utilized the Tokenizer class and pad_sequences module from Keras. After initializing our tokenizer, we called tokenizer.fit_on_texts on both our training and testing sentences. This fit the tokenizer on our data and allows us to generate a word index - a numerical mapping of every word to a numeric representation.
The next step was to encode our training data into sequences. Here we converted our text sentences into their corresponding numeric representations from the word index we just generated. Then we found the maximum sequence length (for use in the padding step).
The final step in tokenization was to pad the training sequences. This is because each sequence must be of the same length in order to be input to our model. Since we already found the maximum sequence length - all we need to do was pad every sequence that is less than the maximum sequence length with 0s. A call to pad_sequences was used to complete our tokenization process.
Model Architecture
The first kind of neuron we utilized were LSTM (Long Short Term Memory) cells. At each time step, an LSTM cell takes in an input vector and a hidden state vector from the previous time step. The input vector is combined with the previous hidden state vector to produce an “input gate” vector, which determines which information from the input vector should be remembered or forgotten. This input gate vector is then combined with the previous cell state vector (which acts as a kind of “memory” for the network) to produce a new cell state vector.
The cell state vector is then further modified by a “forget gate” vector, which determines which information in the cell state should be forgotten. The modified cell state vector is then used to produce the output vector and the new hidden state vector, which will be passed to the next time step.
LSTM cells are designed to be able to selectively remember or forget information over long periods of time, which makes them particularly useful for natural language processing tasks where context is important.
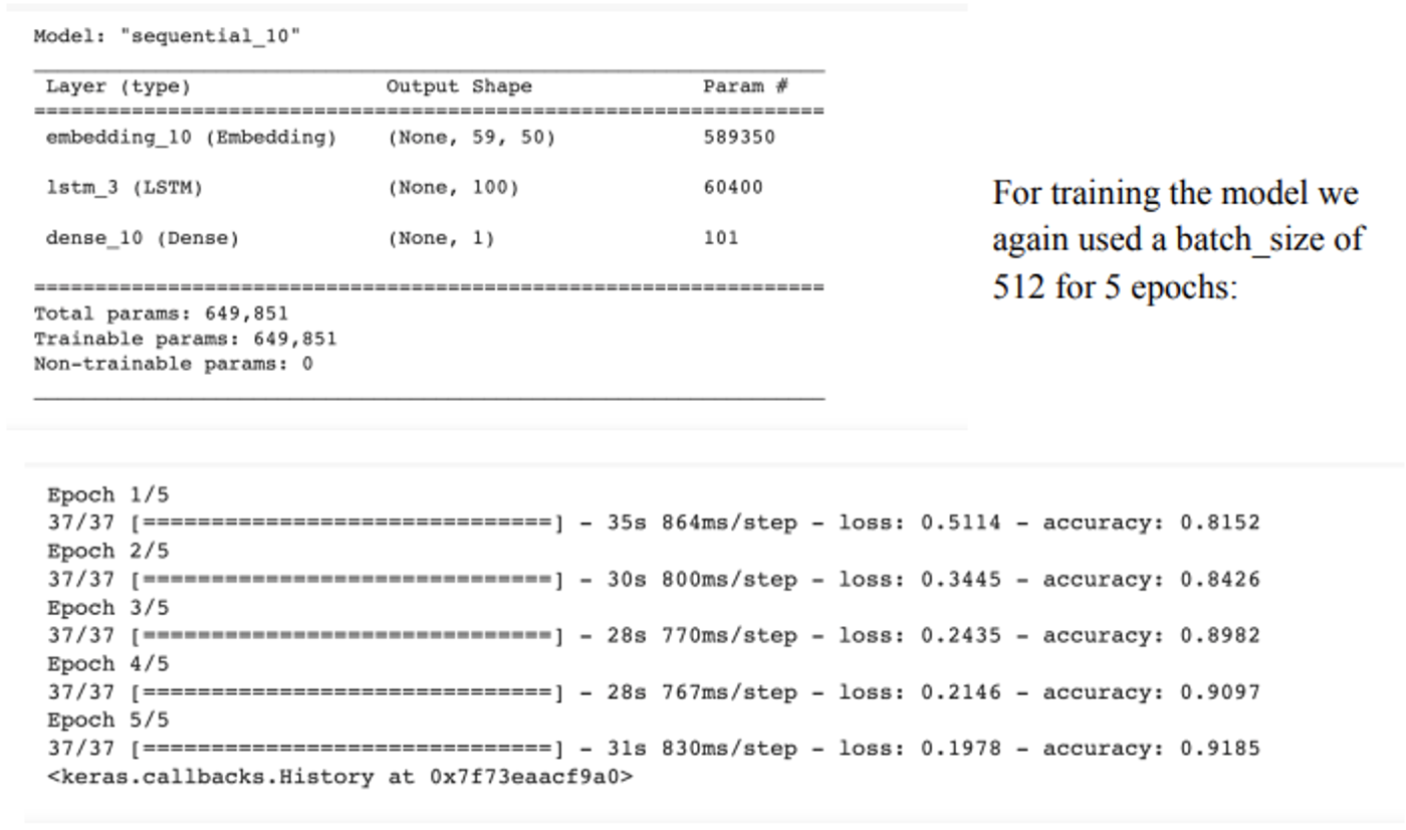
Our model achieved an accuracy of 0.9185 after 5 epochs and an AUC of 92%
Results
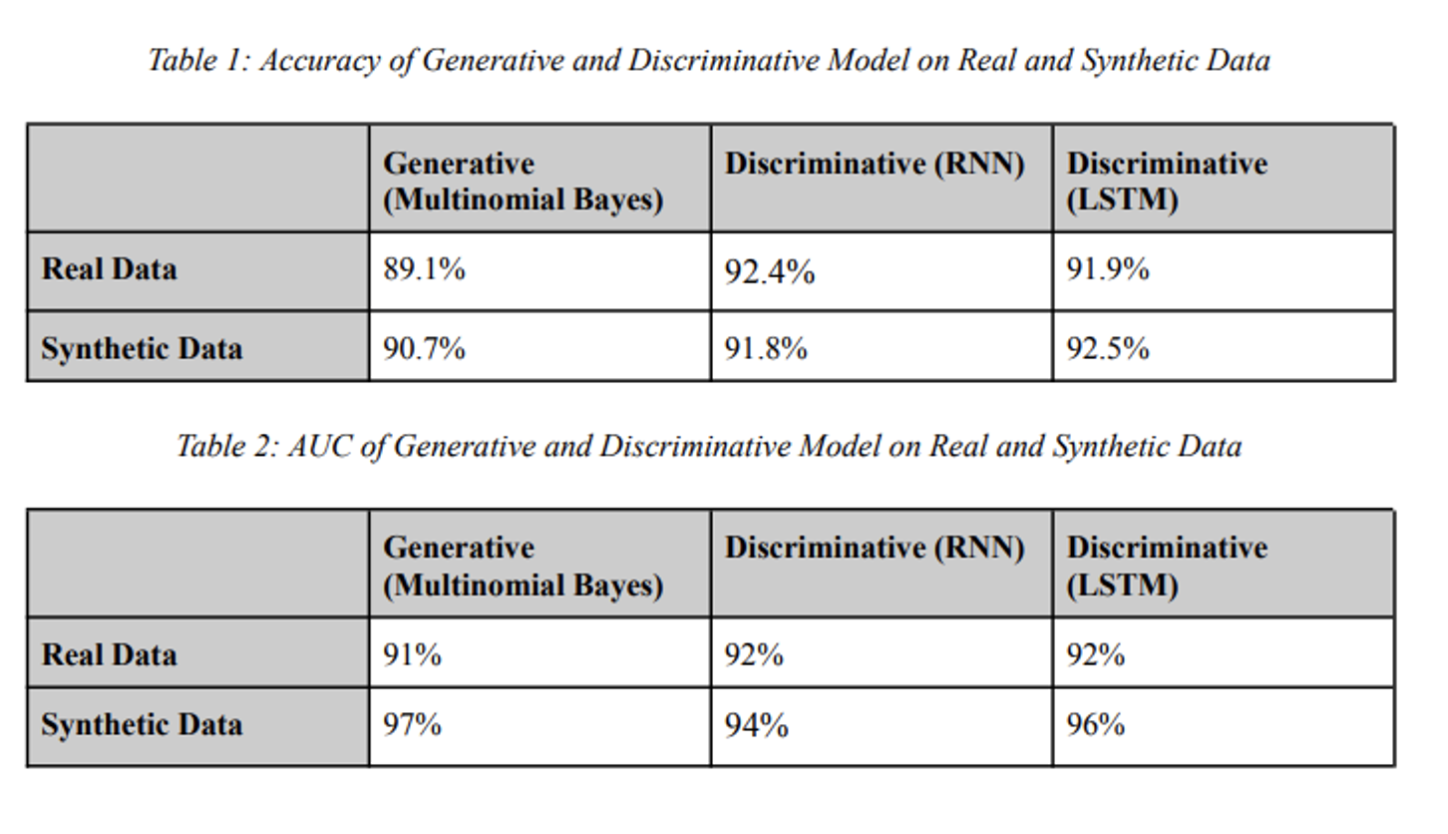
Analysis
To view our full analysis please take a look at the pdf in our gitHub repo. TLDR: The best model isn’t necessarily the one with the best accuracy - it depends on how you want to optimize fore Recall, Precision, and Sensitivity